How to Automate Without APIs by Building Minimal, Safe Interfaces
How to Automate Without APIs by Building Minimal, Safe Interfaces


When Automation Hits a Wall: How to Automate Without APIs
Most mornings lately, I’m kicking off our auto-post pipeline and watching the WordPress API do its thing—except when it comes to Yoast SEO metadata. I’d set everything to push out new blog content, but then realize those crucial SEO fields just aren’t there. You only notice it when you look for them and—nothing.
I’ll admit, I was this close to resigning myself to old-school copy-pasting. Every post, every time. And if you’ve tried this for even a week, you know how fast those manual steps stack up. Your process gets choppier, progress feels slow, and the fun of building turns into “just get it done.” You end up spending your time on the work you never meant to do.
But when a workflow blocks you, it pays to ask how to automate without APIs—where does the data actually live? If the plugin surfaces it on the site, there has to be a storage spot somewhere deeper—not just in the API responses.
Here’s the shift I needed: Just because there’s no API doesn’t mean it’s hard. Sometimes, the solution is sitting one layer lower.
Bridging the Metadata Gap—From Database to Endpoint
The quickest way through any plugin black box is to trace data to source—the data’s real home. With Yoast, the meta descriptions aren’t just floating in API limbo—they actually land in two spots in the WordPress MySQL database. Specifically, you’ll find them in wp_postmeta under the _yoast_wpseo_metadesc key, and also tucked into the description field in wp_yoast_indexable, each tied directly to the post ID. Reference. If you’ve ever wondered why one plugin’s API feels like a maze, it’s usually because the actual state lives close to the database and most plugins just sprinkle headers over their tables, hoping it’s enough.
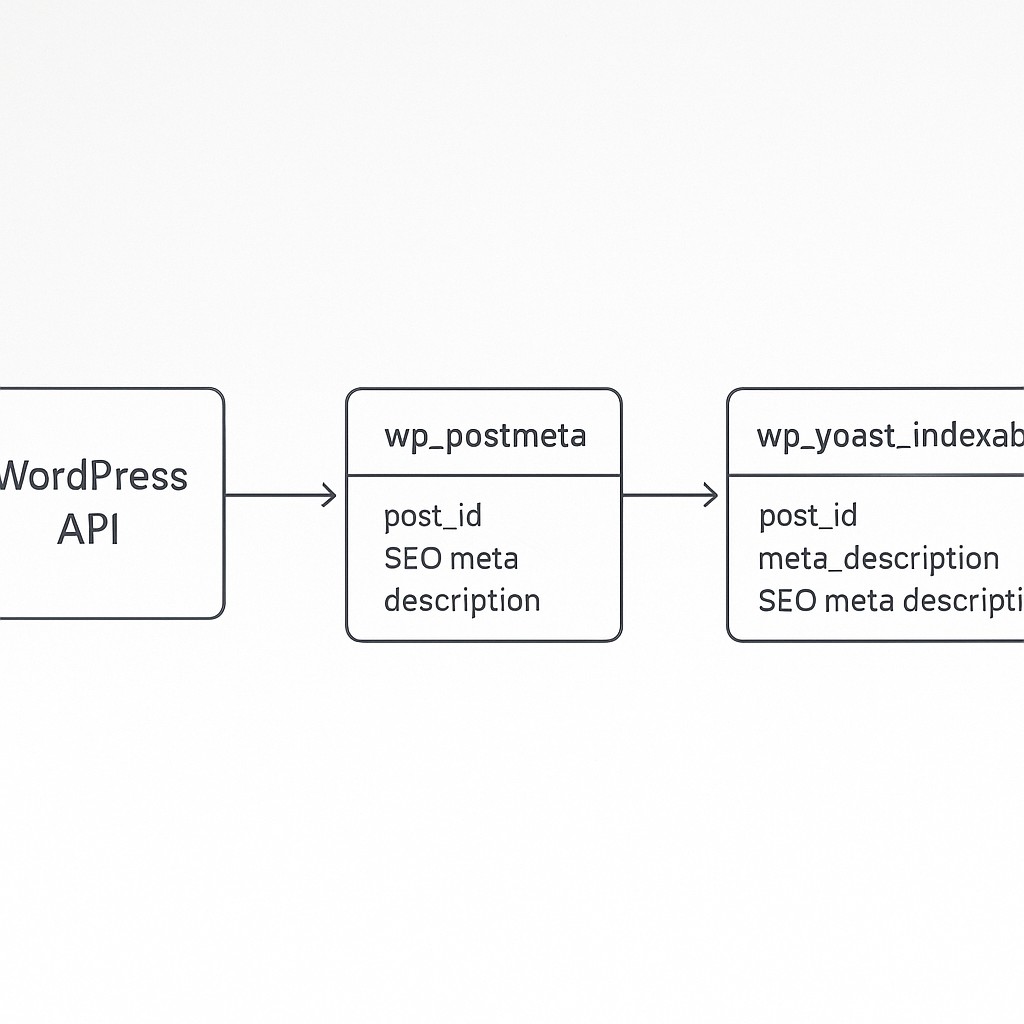
Six months ago, I would have spent a full afternoon poking through every table just to confirm Yoast wasn’t hiding them somewhere trickier. The moment I confirmed where the metadata lived, it was clear: I didn’t need an official integration—I needed the tiniest possible bridge.
So what I built was a thin integration layer—a slim PHP endpoint designed to accept only the fields required for automation, nothing more. I used JSON Schema to put a contract right on the endpoint, making input structure transparent and validating each piece before it gets near your data, which kept accidental writes at bay. No bulky logic, no attempt at a one-size-fits-all API, just a lightweight handshake so our pipeline could go end to end again. I kept the scope ruthlessly tight—only what was needed to unblock automation. The intent wasn’t to build some flagship feature, just to restore automation without opening up new risks.
Here’s where working in Azure’s managed WordPress environment gets interesting. The networking alone is its own puzzle. With jump boxes for shell access, peered VNETs stitching resources together, and private DNS zones that will make you double-take at your connection strings. Getting a minimal endpoint up wasn’t just about server config—it meant threading a safe path between locked-down resources and only allowing the traffic we needed. Small interfaces helped here too. Nothing says “easier to secure” like a script that does one thing and one thing only.
I’d be remiss if I didn’t mention the time I knocked myself offline after updating a firewall rule too aggressively. I was sitting there blank-faced with zero SSH access, and had to call in a favor just to get someone else to roll it back. That awkward pause in progress stuck with me—there’s real cost to moving fast without strict boundaries.
Once all the pieces were wired up, I ran tests to check idempotency. Making sure the same request wouldn’t double-write or blow things up. Those first successful end-to-end runs felt like flipping a stuck switch. Honestly, even after years of engineering, there’s still that little rush when a system finally clicks. Picked up a few new tricks along the way, too.
If you’re reading this and tired of copy-paste clicks in WordPress, this is your way out. No more jumping between database windows and the editor. No more tedious manual steps bogging down your pipeline. You can trace the real storage, drop in a safe endpoint, and take repeatable drudgery off your calendar for good.
Make Automation Possible—Trace, Interface, Guard
Here’s the repeatable pattern. When an API blocks automation, don’t give up—learn how to automate without APIs. Look a layer down and build the smallest safe interface. You’re not stuck; you’re just one step away from making the system bend to your workflow.
First, you want to trace where the data actually lives. Skim past whatever abstraction the tool presents. Dig into the database, the file system, or wherever the actual state is kept. List out every field and operation you need for your workflow, not what the vendor’s docs show or what’s easiest to expose. You’ll be surprised how much gets simpler when you focus only on what’s truly necessary. It’s a bit like mapping your route before starting to drive—figure out exactly where you need to go instead of following vague signposts.
Quick detour: fixing stuck drawers with a butter knife. If you’ve ever pried open a drawer using the end of a butter knife, you know the secret isn’t brute force; it’s precision—a tiny nudge exactly where the jam is. Unofficial tools can be elegant, as long as you’re targeting the real constraint. Interfaces are the same. Minimal, precise actions beat complex, sanctioned solutions that never quite fit.
Once you know your targets, build the absolute minimal endpoint. Skip bells and whistles, but don’t skip safety. Wrap it with authentication and put network boundaries in place so the interface isn’t accidentally exposed to the world. Design it for idempotency and audit. Incorporating a client-supplied id—like Amazon does—lets you spot and safely handle duplicate requests every time (link). Then, test it with the mindset that in six months, you’ll forget how it works. Clear logging and dry-run options can make this future-proof. You’ll thank yourself later when something breaks and you need to debug fast.
Honestly, this is where daily friction dissolves. Well, the data must live somewhere. Finding it—and giving it the cleanest handshake out—restores automation, speed, and sanity when the official path hits a wall.
Addressing Safety, Longevity, and Compliance—Building Minimal Interfaces That Last
I know the nerves kick in right here. Is this safe? Does it really pay off, or am I building a future headache? If you’re asking those questions, you’re not alone—they’re exactly where my mind landed after the first prototype.
Start with safety. If you’re thinking about poking at lower layers—databases, custom PHP endpoints—you want concrete guardrails, not just “it should be fine.” Always prefer reads before writes. Pull what’s there so you’re never guessing. When you do write, do it through database transactions so you avoid partial changes if something fails halfway. Scope privileges mercilessly.
If your service only needs to touch one table, don’t give it the keys to everything. Validate every input, always. It sounds basic, but I’ve seen “just trust the payload” blow up enough times to keep me honest. And log everything—every read, every write, every error, with enough detail to reconstruct what happened later. That traceability isn’t just for debugging. It’s what makes you sleep ok at night when the inevitable surprise rolls in.
Now, let’s talk about keeping this thing maintainable. Minimal doesn’t mean messy. Version whatever interface you build, even if it’s a tiny endpoint. Tomorrow’s changes come faster than you think, and versioning lets you update without breaking things. Document the contract—literally write out what data you expect and return—in a way that’s accessible to anyone working on the pipeline. Wrap configuration in code, not hard-coded values or secretive settings spread across the environment. Add health checks up front that confirm it’s live and responding, and put some honest timeouts in place, so issues can fail fast rather than hanging your jobs.
Compliance gets its own playbook, especially in managed clouds like Azure, AWS, or GCP. Change controls matter. Don’t let “quick fixes” sneak past review, even for seemingly harmless endpoints. Use private networking wherever you can, so exposure is as limited as possible. Keep audit trails for every operation; they’re your best defense when someone asks “who changed what, when and why?” The good news: every major cloud has built-in tooling for these—Azure Monitor, AWS CloudTrail, GCP’s Operations Suite. Tap those, bake them in, and your endpoint won’t become a compliance headache six months down the road.
There’s still one piece I wrestle with. Despite every best practice, some secrets inevitably slip into the wrong place—an env var in a shell session, a leftover password in a config file. I haven’t cracked the perfect secret hygiene, and honestly, sometimes I still stash a token somewhere just to get things moving. It nags at me, but for now, that’s the honest state.
Keep your pipeline moving by generating AI-powered drafts your automation can publish, so you spend time building small, safe interfaces instead of writing from scratch and copy-pasting metadata.
If you’re still wondering whether all this effort is worth it, here’s the reframe. A small, safe interface can save you hours of daily manual work and wipe out months of brittle hacks or delays waiting on vendor-supplied features. Your move: Don’t accept friction just because it isn’t wrapped in a bow. Sometimes, the solution is just one layer deeper.
Scaling the Pattern—One Layer Down, Many Domains
It’s funny—once you’ve looked below the surface to fix a bottleneck in WordPress, you start spotting ways to automate around missing APIs everywhere you build. It pops up in content pipelines, where a CMS hides the fields you actually need behind an API that’s “mostly” complete. I’ve hit this wall with ML ops too. Signals you want to route are just sitting in a database column, but official orchestration tools won’t touch them. If you’re running internal platforms, odds are something critical lives beneath the UI veneer, quietly trapping automation behind manual updates. The association is clear.
Almost every sturdy system you build eventually runs into this. Don’t wait for an integration; get curious about where the data really goes, and address what’s missing directly. If you’ve landed here, keep going. It means you’re one step away from unblocking your next workflow.
Here’s what actually works, in the real world. Start by inventorying your friction points—every spot in your flow that feels needlessly manual or error-prone. Trace the actual data paths underneath those surfaces, and you’ll almost always find that the “unavailable” field is just sitting there waiting for you. Pick one specific interface to build this week; it feels like a small task, but each win adds up. Block off a couple hours, aim for scope so narrow it feels silly, and ship it.
Within a few days, you’ll see the daily payoff. Less clicking around, no more brittle glue scripts duct-taped over gaps. Your workflow, finally humming on its own, can bypass tool limitations—immune to yet another vendor roadmap delay or breaking update. It sounds almost minor, but it’s the difference between systems you nurse daily and ones that just work.
By now you’ve seen the callback. Capability is almost always present somewhere lower in the stack. You don’t have to wait for permission or veneer. Just because there’s no API doesn’t mean it’s hard—you just need to reach down one layer and connect the dots.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.
You can also view and comment on the original post here .