How to Quantify Technical Objections: From Dismissal to Discovery
How to Quantify Technical Objections: From Dismissal to Discovery


From Dismissal to Discovery: Why “Too Expensive” Rarely Tells the Whole Story
“We tried it. It failed.” That was the line I kept hearing from the client’s data team last May, and the kicker was always the same—Azure Batch, written off before it had even gotten a foothold. I asked when, I asked how, and what I got were shrugs and sideways glances. It’s easy to nod along, but I held back. Something about that quick verdict didn’t add up.
The second objection landed just as hard—“Too expensive.” I hear this in nearly every cloud pitch that goes sideways, but without real numbers, it’s a label, not a diagnosis. You’ve probably caught yourself doing it too, shelving a tool, not because you ran the math, but because someone somewhere insisted it’s a budget killer.
I treat these statements as prompts for how to quantify technical objections by turning labels into measurable questions. When someone says “It failed” or “It costs too much,” I want details. What failed, under what input, compared to what baseline? Where’s the actual breakdown? Staying curious here isn’t optional—it’s how you unlock what’s really possible.
People make qualitative claims about quantitative problems. “Fast,” “slow,” “costly”—none of these mean anything until you attach specifics. You’ll see objections tumble when you start turning them into questions. How much exactly? How well did it handle 50,000 jobs versus 500? Was the expense in compute, or in wasted overhead?
If you stick around, I’ll walk you through how to map every “too expensive” to an explicit cost-per-outcome and teach you first-principles analysis that turns uncertainty into actual control.
Reframing “Too Expensive” with Supersonic Clarity
There’s a moment that sticks with me—watching Blake Scholl break down why supersonic passenger flight didn’t die because it was “too expensive,” but because nobody bothered to actually quantify what that meant. No one had the numbers for cost per seat, or the real barriers standing in the way. It was just “too expensive—end of story.” And that mindset hit home for me because I’ve seen the same shortcut kill technical options again and again. Whenever I catch myself nodding at a price headline without context, I remember: “Too expensive” isn’t a final verdict. It’s the first step—a sign nobody has bothered to measure, compare, or even define what “expensive” should mean for the job at hand.
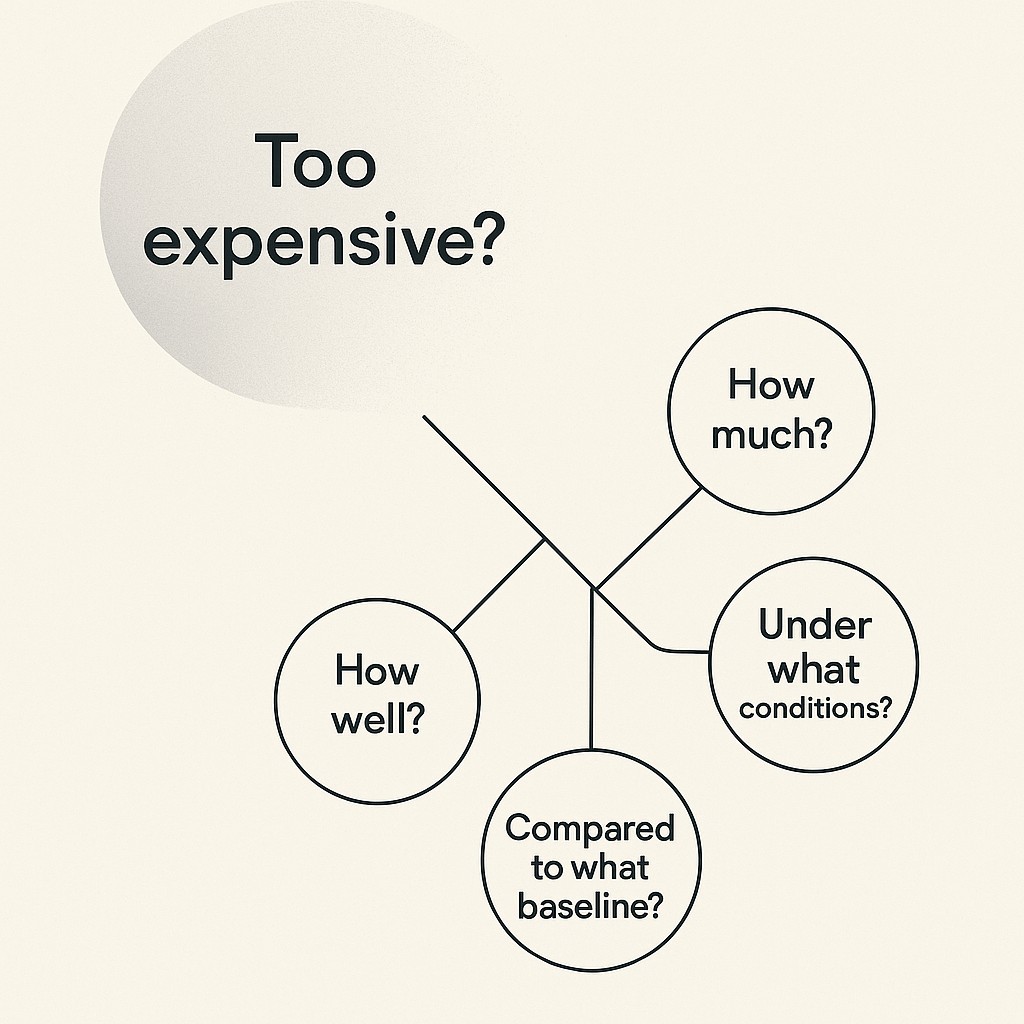
So here’s the shift. You stop accepting lazy objections and start with four direct questions that let you measure qualitative objections. How much? How well? Under what conditions? Compared to what baseline? It’s amazing how often those are missing from even the most technical debates.
When you push tools and experiments through that filter, you start by clarifying the workload shape, the operational setup, and getting baseline metrics nailed down so you can normalize ranges to build trust before anyone votes yes or no. Don’t argue feasibility until you know those details.
It’s totally normal to worry about uncertainty here, especially when the numbers aren’t easy to get or the path looks messy. The move is to get honest and write down, “what must be true for this to succeed on our terms?” Set clear, measurable success criteria that tie back to your goals—the only way experiments yield answers that matter to you (link).
The Workflow: How to Quantify Technical Objections by Turning Qualitative Claims into Quantitative Answers
Start treating objections the way you’d triage a bug report in production. Named, scoped, repeatable. If someone says “it’s too expensive,” that’s just like a bug with no stack trace. It means nothing until you nail down the circumstances, inputs, and what “expensive” looks like in context.
First step, spell out the workload and setup in plain terms so you can quantify engineering objections. Quantify the job—are we talking about handling 10,000 short-lived jobs, or a handful of ten-hour deep learning runs? Write down concurrency levels, I/O patterns, data sizes, and which batch configuration options were toggled. Ask out loud: “for what workload? under what setup?” If you can’t get those details, don’t even try to debate outcomes.
Next, define your baseline and what “winning” means. Don’t just say “faster” or “cheaper,” anchor it to metrics you care about. That could be throughput (jobs per hour), tail latency (not just the average, but P95 or P99 so you capture the worst cases), error rates, and the maximum spend per run that your business can tolerate. Many performance teams use P95 or P99 instead of averages when defining acceptable response times in SLAs, which reveals realism over feel-good numbers. That’s the real snapshot, not the marketing version.
Then tie costs to outcomes, directly connecting spend to delivered results. Stop reading the cloud invoice in a vacuum—connect every dollar to what it accomplished. Compute ROI on a per-job, per-batch, or per-output-unit basis, so when the bill comes in, you know what the compute achieved. By measuring direct on-demand infrastructure costs alongside transaction counts, you generate a grounded metric. Cost per transaction that anchors ROI to reality.
Finally, design the absolute smallest experiment that will cut the uncertainty to get buy-in with pilots. This isn’t just about time or money. It’s about paring the scope until you can get a directional answer without blowing up your schedule.
Once—this still pops into my head—I spent an entire Tuesday afternoon trying to chase down a weird spike in job failure rates, only to discover the root cause was that someone had toggled a config flag at 2am the night before. Of course, nobody remembered doing it. The log files were all timestamped, but the culprit was a random one-off test script buried in a shared directory dated six months ago. Funny how the smallest moment can throw off a week’s work, but it’s the same way with cloud objections. If you don’t chase specifics, you’ll keep fixing the wrong things.
This workflow doesn’t take away the hard thinking, but it does focus it. You’ll still face friction—especially with incomplete data or internal inertia—but now you’ll have a repeatable way to call out, close gaps, and push objections from “it feels wrong” into “here’s where it breaks (or doesn’t) and what that break actually costs.” That’s where better decisions start.
The Azure Batch Turnaround: Breaking Down “Too Expensive”
The first invoice was a knockout punch. We’d barely gotten Azure Batch spun up before the finance team had red flags all over it, line items that didn’t match expectations, frustration mounting with each column. The verdict was swift: Azure Batch, scratched off the roster, ‘too expensive to justify.’ All of this happened in a single quarter, before anyone paused to ask if the numbers made sense for what we were actually running.
Here’s where it started to unravel. The team had thrown a generic workload at Azure Batch without considering how the service was meant to operate. Job sizes ranged wildly, concurrency limits weren’t set, and everything defaulted to the highest available resource pool. If you ever find yourself dismissing a tool after seeing a scary bill, ask: “Did we match the workload and setup to the tool’s strengths?” Because most of the time, those early objections map back to mismatched patterns, not inherent flaws.
Our fix wasn’t magic—it was method. We broke the workload down into bite-sized job units, dialing in the pool configuration so machines spun up and down according to actual demand instead of worst-case guessing. For example, we moved away from launching giant pools for five jobs and instead mapped pool size to real concurrency needs: scaling up for high-throughput nights, scaling back for downtime. Task grouping got tightened.
We ran tests on different VM sizes, measured per-job runtime, and discovered the sweet spot between wait times and cost as we weighed reversible technical tradeoffs. With those numbers in hand, we turned Azure Batch into a processing powerhouse. What was once a budget sink became the backbone of our data pipeline, crunching thousands of jobs—on budget and at speed.
But the real flip wasn’t just technical. It was about perception. I recognized the team’s invoice fixation; those “headline” totals looked brutal out of context. So I brought everyone back to the product: what did the compute deliver? Instead of debating sticker shock, we compared cost-per-output against our legacy toolchain. Every dollar spent translated into a concrete pile of processed jobs, not just raw hours on a VM. The old manual workflow burned man-days and ran at a fraction of the throughput. Azure Batch looked expensive until you mapped cost directly to delivered outcomes—and suddenly the value was vivid, not abstract.
Why did all that work? Batching cut out redundant setup steps and idle time, letting us streamline resource usage. The job graph matched up perfectly with parallelism—Azure Batch’s real edge—so jobs zipped through instead of bottlenecking on serial waits. Our configuration aligned resources tightly with job types, moving from all-purpose blobs to specific pools that fit each workload. The more precisely we defined the config, the less overhead we paid. By the end, everybody saw that the right fit beat the right headline every single time.
I should probably admit—sometimes I still catch myself fixating on the scariest line items before zooming out to see what they actually paid for. The tension never fully goes away. Maybe it shouldn’t.
The Habit That Turns Objections Into Opportunities
Let’s be honest. Nobody has unlimited time, perfect data, or the patience to slog through sunk-cost bias. I get it—you’re busy, and the idea of picking apart every objection feels like a lot. But here’s the upside: you don’t need heroic analytic sprints, just small, deliberate experiments. As soon as I started running bite-sized tests instead of overthinking the gaps, my confidence shifted. If you feel boxed in by patchy information or worry you’re too stuck in your old decisions, start small. Write down what’s missing, name the sunk-cost bias out loud, and let a quick experiment nudge you forward. The messiness never totally disappears, but clarity always wins a little ground.
That “incomplete bug report” question I pushed for earlier is what actually changed my habits. It’s now my checkpoint before every technical post-mortem or invoice review. Ask for specifics or wait for the details—don’t settle for labels. It’s a small thing, but it’s made it easier to spot patterns that would otherwise slip past if you let the summary headlines run the meeting.
Engineers and AI builders, use our AI to generate technical posts, summaries, and CTAs tailored to your goals, constraints, and tone, so you can ship clear content fast without wrestling prompts.
If you want a repeatable way through the fog, use this checklist to evaluate architectures quantitatively. Jot down the specific measurable questions (“What is the cost per job for our actual workload?”), set a fit-for-purpose baseline and explicit success criteria, connect every cost to a direct outcome (not just the invoice total), and run the smallest experiment that gets you a real answer. Don’t wait for perfect data. Design the test that slices uncertainty down just enough so you can move.
Make “how to quantify technical objections” your daily practice. Every new tool, architecture, or off-the-shelf experiment—reach for those questions first. By asking them daily, the rigor stops feeling like work and starts becoming reflex. Even jotting a two-minute note before a meeting can surface daily insights that shift your perspective over time, not just on big-ticket projects.
So next time you hear, “it costs too much,” pause and reframe it: “How much, for what, under which circumstances, compared to what baseline?” That line is your launchpad. It flips the story from fuzzy complaint to concrete challenge—one you can actually solve.
Tie cost to outcomes, and spell out what success means before you pronounce an effort a failure. This single shift will save you from tossing real opportunities overboard just because the surface feels rough. If you do nothing else, do this.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.
You can also view and comment on the original post here .