Build reliable LLM pipelines that ship, not demos
Build reliable LLM pipelines that ship, not demos


Why Prompt-Centric AI Hits a Wall
When I first started working with AI, I really did believe prompt tuning was the heart of the job. I’d spend hours tweaking little phrases, swapping out a word, adding a clarifier—every shift felt like a win. Looking back, those were the moments I thought I was unlocking something, but really, I was just circling the same track.
That held up for a while. Demos looked snappy during team reviews, outputs made sense in the narrow cases we showed off. But as soon as those prototypes touched actual production data, we realized we had to build reliable LLM pipelines—otherwise things fell apart. What worked on Tuesday failed against Thursday’s edge cases, and I was right back in the weeds.
There’s a memory that sticks from those early weeks—I kept a MacBook running three separate prompt files, each named after the weird bug it had fixed. For a while, I genuinely thought this system was clever. Turns out, all I did was build a hidden maze of one-off solutions nobody else wanted to touch. It made demos sing for a minute, but the maze collapsed as soon as a new request came in.
Here’s what kept breaking: brittle logic that lived and died by a single word, invisible assumptions baked into prompts, and errors that you’d never spot until users tried something different. Tweaking one prompt led to another round of “just one more change,” and suddenly, teams were trapped in endless cycles of rewording, chasing reproducibility that never stuck. We weren’t building systems—just patching demos. Every retro spotlighted the same gaps. Changes didn’t make outputs more robust, they just shuffled problems forward.
The truth is, the path forward lies beyond prompt engineering. They’re just inputs. Durability comes when you specify the task—not just the wording—and build the system around it.
The Anatomy of a Task: The Unit That Actually Delivers
Six months ago I was still caught up in the thrill of clever prompts, but things changed fast once I saw the limits. In task-based AI design, think of a ‘task’ in LLM features as the true building block—the atomic unit that does the job, owns the context, and knows what good looks like when it’s done. If you’re trying to ship reliable AI, you have to switch your mental model. A task is holistic. It’s not just about sending in a prompt and hoping for the best. It bundles everything that defines success, so you can actually test and trust what comes out.
Here’s a simple way to picture it. A prompt is only one slice, like an argument you pass into a function. The function—the task—packages up context, intent, rules, and the shape of valid results. You wouldn’t ship a feature where all the logic depends on the exact wording of one argument. Tasks give you the scaffolding. They own the contract, not just the phrasing.
Let’s break it down. In effective LLM task design, each task wraps up its own context (like the data, the user’s goal, or relevant history), clear parameters, the specific behavior you want to run, an output structure you actually care about (say, a JSON object with fields), and checks or validations to prove it worked right. Instead of flipping levers blind, you build guardrails in from the start, and you see uncertainty shrink, fast. No more “maybe it’ll work if we tweak it.” You get failures you can diagnose, outputs you can measure, and the ability to improve without playing prompt whack-a-mole. The first time I set up a task like this, I stopped dreading deployment day.
Here’s why LLM pipeline observability matters. Tasks emit the signals, logs, and results you need to measure what happened, retry failed steps, or escalate when things go sideways. Troubleshooting actually depends on end-to-end visibility into task chains—which makes solid monitoring tools essential for real, actionable feedback across steps. You can’t fix what you can’t see, and tasks give you the lens you were missing when everything was a fuzzy prompt.
Once you’re specifying tasks cleanly and chaining them, reliability gets compounded. Specialized, smaller LLMs can deliver performance on focused tasks that rivals much bigger general models—which means chaining tailored units really pays off. That’s how you move from demo to durable feature.
Where Product Value Accumulates: Build Reliable LLM Pipelines with Seams and Interfaces
To build reliable LLM pipelines, think of a pipeline as a string of tasks, each with its own contract, handshake, and fallback plan. Instead of tossing a prompt into the void, you set up handoffs—one task finishes, passes its results in a known format to the next, and if something goes sideways, you have a path to retry or bail gracefully. That’s the difference between hoping for success and engineering for it. It’s less abstract theory and more like designing subway stops. Predictable routes, clear transfers, minimal surprises.
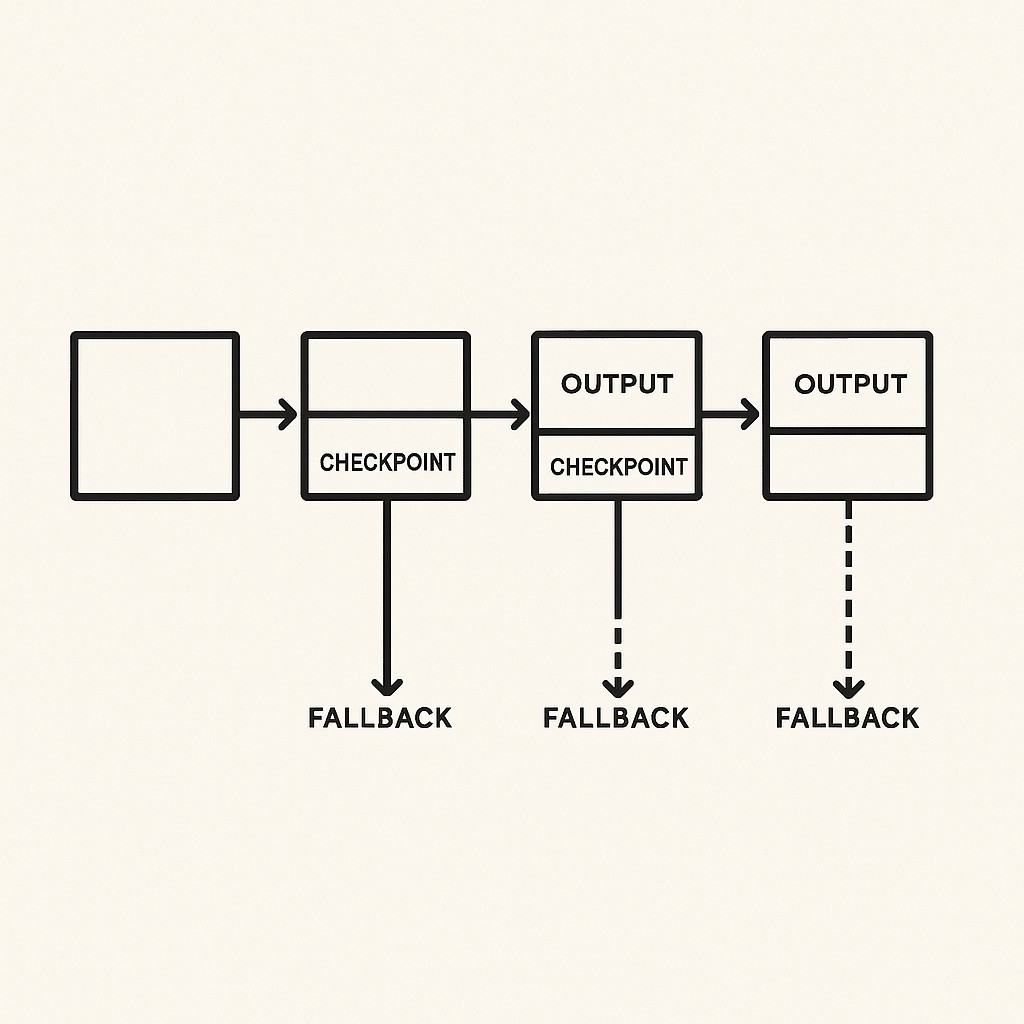
Let’s walk through one. Picture a pipeline that starts with retrieval (gathering docs), goes to summarization (getting the gist), then classification (deciding what bucket it fits in), and finishes with enrichment (adding extras). Every step deals with its own failure modes. So, retrieval grabs relevant docs. If it gets nothing, you trigger a smart retry (maybe widen your search criteria, add a wait). Summarization runs next—if output isn’t parseable, you back off or flag for manual review. Classification gets the clean summary and slots it by type; if confidence is low, you hand off to an alternate path or log for feedback. Enrichment only runs if upstream delivered, adding context or tags.
If you want to see how this compounds, look at pipelines where multi-round retrieval chains layer reasoning by alternating retrieval and generation steps, so answers get refined as the pipeline runs. Each hop is a checkpoint. Now, if one link falters, you know which, and you can fix it without undoing the whole chain.
It’s sort of like dialing in your coffee routine. The grind, the dose, the water temp—they each have guardrails. If the grind’s wrong, you tweak just that before messing with the rest. Predictable, contained steps. You don’t throw the whole cup out because one variable’s off.
Here’s the shift in plain words. Prompts spark experiments. Tasks deliver repeatability. Pipelines build products. If you remember one thing, let it be this.
Now, I get the hesitation. Does chaining tasks and adding guardrails mean heavyweight frameworks or endless boilerplate? Doesn’t have to. You can start light. Simple templates, small modules that define inputs/outputs, and wrappers for retries or basic checks. Half the time, it’s about naming steps clearly and passing data in formats your next task knows how to read. If you’re worried about complexity, build out just enough to see errors and logs. That’s usually all it takes to spot the patterns and get traction. The scaffolding can grow with you. It doesn’t need to slow you down out of the gate.
Ship Faster: Making Task-Centric AI Concrete with a Reliable Internal Package
Once the task model finally clicked, building an internal package was just obvious. The urge to keep nursing prompts as magic spells faded out. I’d spent enough cycles fixing brittle hacks; standardizing real specs and workflows was the only way forward.
The package’s core API turned out pretty simple. You define task specs up front—context, parameters, behavior, expected outputs, and built-in checks. Then you compose repeatable pipelines from those tasks, attach retry logic or guardrails, and wire in instrumentation for all the observability bits. This setup lets you chain tasks like Lego. Swap out modules, trace results, and catch failures automatically. Instead of experimenting with another clever prompt each week, you build systems you can actually trust.
Let me give you a sense of velocity here. With the package in place, spinning up a new flow—a mix of retrieval, summarization, classification, enrichment—takes hours, not days. You just plug together proven building blocks. The big difference is that you don’t have to reinvent safety checks or logging for each job; it’s all baked in. You’re not wrestling with prompt quirks anymore. You’re just managing tasks.
The best part is what you now see, not just what you build. Each task emits traces and structured logs along the way. You get quality signals in real time, and if a hiccup happens, alerts fire automatically. That triggers retry logic or bumps a case for human review, depending on what’s broken. Instead of pulling your hair out over “why did this fail?” you get a clean audit trail, concrete error types, and dashboard visibility into every step. You can finally answer the real engineering question—“Where, exactly, did this go off the rails?”—and fix it on the spot.
That’s how you ship features that stick, not just flashes in the pan. Task specs make work observable, pipelines compound reliability, and the package turns invisible complexity into signals you can see and trust. The earlier you adopt it, the faster real progress comes—no magic spells needed.
From Demo Complexity to Durable Pipelines: Dismantling the Barriers
I’ve felt the tension around complexity and “will this really be worth it?” plenty of times—it’s a legitimate worry. Moving from “just tweak the prompt until it looks right” to a whole new system feels like DIY risk. But here’s the reality. Layering in real scaffolding early reduces firefighting later. When you invest a bit up front in reliable moves, you cut risk and deliver repeatable wins instead of another brittle demo.
If you’re ready to step out of endless prompt tuning, start small. Pick just one task—say, document classification or answer rewriting—and write down what success looks like, in clear terms. Add AI guardrails and validation, even a basic step. Chain it with a second simple task (retrieval, maybe). With those, wire in retries for failures and set up one guardrail (like a format check). Log every result and note where things freak out. That’s it. Don’t over-engineer. Just get observable signals and make failure visible at each step.
From there, here’s what pays off. Shipping gets faster, not slower. Debugging is straightforward. Failures flag where in the chain things broke, so you don’t chase ghosts. Every new feature builds on the last, reusing task specs and scaffolding. Reuse starts compounding. And the best part is, the value grows as you add tasks. The difference between a fragile prompt and a robust pipeline gets clearer each release.
Create AI-powered drafts with clear structure, your preferred tone, and simple controls for edits, so you can ship posts, emails, and docs quickly without wrestling with prompts.
Funny enough, I still catch myself fiddling with prompt wording even when I know what the pipeline needs. Old habits hang on. Maybe that’s the last bit of the maze I haven’t left behind.
You’ve tweaked prompts enough. Try mapping out your first task, plug in a guardrail, and chain it. Commit to building a pipeline with observable steps—your future self will thank you for making AI features you can actually trust.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.