Design resilient LLM workflows: from fragile chains to fault-tolerant systems
Design resilient LLM workflows: from fragile chains to fault-tolerant systems


When One Broken Step Halts the Whole Flow
I started with a pipeline I managed mostly by hand, step by step, checking things as I went. Then, finally, I wired it all into one automated flow. You know that feeling? Pride mixed with a small, persistent doubt lurking in the back.
The very first failure hit hard. Suddenly, when one step failed, the whole thing jammed. Everything else stopped cold. Even a prompt that works well on one model can trigger instability—sometimes you’re staring at a 13% performance hit—when swapped to another (see CB, DBPedia). That’s not just a minor annoyance; it shows every brittle spot instantly.
What really stung: I couldn’t just re-run one piece, underscoring the need to design resilient LLM workflows. If something broke, I was stuck restarting the entire chain. No shortcuts, no workaround. Every retry felt like rolling a boulder uphill.
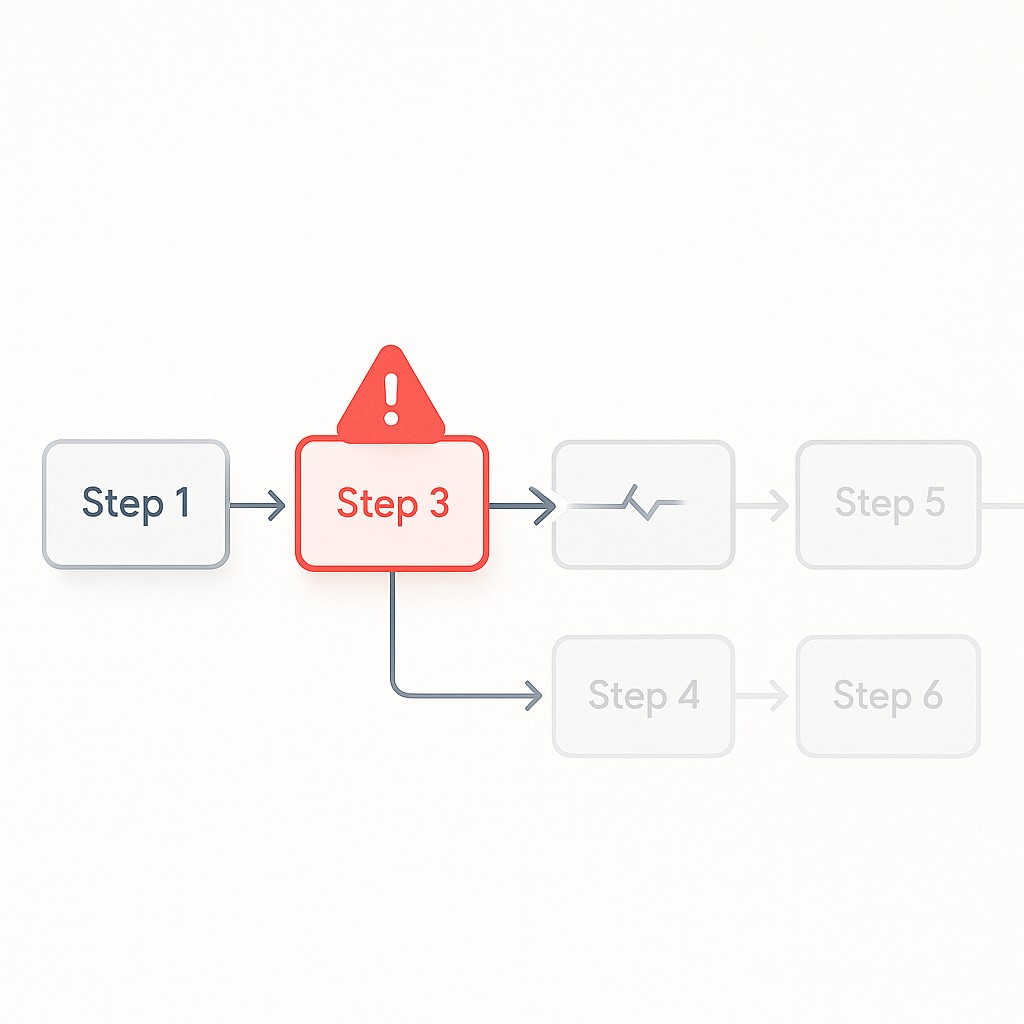
That was the moment the real problem came into focus. Retries, conditions, and anything resembling automated decision-making weren’t just missing—I hadn’t even considered them from a design standpoint. If your AI workflow has retries, decisions, or memory, you’re not just writing prompts anymore. You’re building systems. Like any system, it needs patterns to prevent one hiccup from spiraling into a stall.
Here’s how I stopped duct-taping and started designing.
Rethinking Prompt Workflows: Design Resilient LLM Workflows From Glue to Real Systems
It’s easy to treat prompt chaining like clever glue. You string outputs together, hope for the best, and maybe feel a little amazed when it sort of works. But that approach falls apart the first time a failure goes silent, or you get slow data rot downstream. The real shift comes when you approach prompt pipeline design and look at these workflows as modular, observable, fault-tolerant pipelines. Every step should be a pluggable, testable unit, ready for transparency and recovery—not heroic rescues.
To get there, you need tight step interfaces. Each part of your flow should work like a contract, transforming data predictably. Draw sharp boundaries between what’s handled by your code—the if-statements, loops, error handling—and what gets sent off to the LLM. Simple logic? Let code do the work. As soon as there’s fuzziness, hand it over to the model, but only when you truly need to.
Truthfully, I still see people reach for an LLM too soon. If you’re just picking based on a fixed label or doing conditional routing in LLMs, an if-statement will almost always beat an LLM on speed, simplicity, and cost. Save model calls for genuinely difficult tasks, not easy logic checks.
Observability isn’t optional. It’s the only barrier between you and mysterious bugs. Log every input, output, and error at every step. Trace failures back to source, not just the big crash at the end. You truly need more observability than you think, because silent errors always find new ways to sneak through unless you’re actively watching for them. Six months ago, I used to brush past tracer logs for “obvious” steps, and got burned almost predictably. The guardrails matter.
Wiring in retries, interfaces, and tracing does force you to work upfront. But what looks like extra complexity now is just investing in the future. The fires you prevent later will pay back every extra minute you spend today.
Robust Design Patterns for Reliable Prompt Pipelines
Picture your LLM workflow architecture as a directed acyclic graph—a DAG—where each step is a node with clear input and output types and, ideally, idempotency. If you run a step twice with the same input, you should get the same result, with no weird hidden side-effects. Data moves from one transformation to the next, instead of tumbling down an opaque chain. When you frame agent flows and toolchains this way, their glue code melts away and you’re left with modular, understandable parts.
Isolation between steps is the payoff. When something fails, don’t wipe the slate clean. Use caching and checkpointing—save each step’s result so you can replay from any point. With replay, you pick up the flow anywhere, not just at the beginning (Dapr workflow replay). When that landed in my pipeline, everything stopped feeling brittle and started working like a true system.
Still, isolation isn’t enough. You need quality gates. Don’t let iffy outputs slide through because “the model didn’t error.” Start with schema validation: did the response match what you actually wanted? Acceptance thresholds—did it meet the score or include the key fields? Add rule-based guards for trickier errors, like mismatched entities or fuzzy results that might foul up later steps. These gates should trigger early and often, stopping weak or risky results before they ripple out. Debugging a silent bug ten hops downstream is a nightmare. I treat each gate like a traffic cop—halting, retrying, or escalating if the output isn’t solid enough. Strictness now saves headaches later.
Retries keep systems alive. Don’t just smash the retry button. Use exponential backoff, spacing out attempts longer each time so you don’t pile up failures (the best retry handling uses exponential backoff for exactly this reason). Sometimes it’s just a weird model blip, sometimes a flaky API. Mix code logic (“retry up to three times, then fail”) with model-driven fallbacks (“let the model try again with revised input”). This is real system engineering, not just prompt scripting.
Last week I was trying to troubleshoot a flaky step in an agent workflow. Out of nowhere, I noticed the machine in my garage humming at exactly the same rhythm as my retry logic—every failed step, a short pause, then another attempt. I watched it cycle for ten minutes before realizing the analogy: when a system jams, some outside sensor is always humming, waiting for a clear signal. It reminded me how layers of detection and retries—like a coffee machine checking its filter—don’t just solve problems, they help you listen for them. These details are small but somehow changed how I design checks.
Put all that together, and you move away from patching prompt failures and start architecting for real-world production. That’s where you finally get some peace of mind.
Instrumentation and Quality: Building Confidence in LLM Workflows
When building these flows, logging inputs and outputs is table stakes for AI pipeline observability. If you don’t capture exactly what goes in, you’ll never fully trust what comes out. Make sure to save the prompts as they’re sent—along with any tweaks you make mid-flow. It’s the only defense against prompt drift or subtle anomalies. Decisions—model choices and code branches—matter, especially for debugging; you need to track why your pipeline took a certain path or went off the rails. Cost tracking per step helps avoid painful cloud bills. Latency shows where execution gets stuck. When things break, you want all these signals at your fingertips.
Tracing connects everything. You want spans tagged so you track every call from start to finish—the difference between scrambling through scattered logs and seeing a clear chain. Without traceability, a single missed retry or subtle routing mistake hides forever.
Don’t let quality slip quietly by. Plug in instant controls—scoring outputs, enforcing rule checks, and sometimes involving human reviewers for critical steps. If an answer isn’t good enough, gate it before it poisons downstream. You’re not just catching obvious failures, you’re catching “quiet bad” before it spreads.
Even solid online checks aren’t enough. Harden your workflow before going live. Curate golden datasets—real cases that force your flow to prove itself. Run regression checks so code or prompt changes don’t break things. Watch for output drift, catch it early. And don’t skip failure tests—force errors, simulate a jam, watch how your logic recovers. I used to let this slide, thinking my manual checks would cover the bases. They didn’t. The more routine I made offline evaluation, the fewer disastrous surprises caught me once real users hit the pipeline.
Start simple—a sturdy log file and a basic span tracker cover the early ground. As complexity grows, add dashboards and evaluation harnesses for full coverage. Fancy tools don’t matter on day one. Clear signals do. When something breaks, you need to pinpoint where.
Blueprint and Migration: Upgrading Your Prompt Pipeline, One Step at a Time
You want a foundation you can rely on. Start lean: apply LLM orchestration patterns—set up an orchestrator, map out steps as modular nodes, and enforce typed input/output contracts. Wrap every step in a function, make all the boundaries explicit. Build control flow so you know when you’re dispatching to the model versus branching with code logic. Keep it simple to start—layer in retries only for common failures, and position early gates so bad data doesn’t get far. This one structure—typed steps, orchestrated flow, observable retries and validation—moved me beyond fragile chains and into reliable systems. Brittle failures fade, recoverable ones become the norm.
How did I move? First, I wrapped my awkward old chain with a thin orchestrator—just enough to add logs and assign unique IDs to each job. Then came checkpoints, saving each result as it landed so I could replay from anywhere instead of clearing the slate. Only when I could trace issues did I tack on gates and retries, filling in gaps as real failures stung instead of trying to future-proof everything up front. If you’re running step-by-step, take these transitions as they come—start small, keep scope sane, add safeguards as needed.
If you need to produce clear, on-brand posts, threads, and docs fast, use our app to generate AI-powered content with editable drafts, reusable templates, and instant exports.
Why all this work? It’s not for style points. The real win is smoother recoveries, fewer “why is it broken?” incidents, and manageable cloud bills. But genuinely, sleeping easier on-call is the hidden payoff. When it’s a system—not just glued steps—the stress drops and confidence climbs. I haven’t figured out the perfect way to handle decision logic that mixes fuzzy LLM results with strict code gating. There are always edge cases, and I still get stuck sometimes. But now recovering isn’t a fire drill. It’s routine.
So that jammed pipeline where one broken step froze everything is exactly why you design resilient LLM workflows. By stacking deliberate engineering patterns on top, you move from patchwork fixes to workflows you can trust—for today, next month, and whenever things actually hit the fan.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.