LLM Prompt Engineering Best Practices: Clarity Under Constraint
LLM Prompt Engineering Best Practices: Clarity Under Constraint


It’s Not the Model—It’s the Prompt
Ever write a prompt, get nonsense back, and immediately think, “this model sucks”? That was me just last week, actually—staring down a wall of useless output, resisting the urge to swap models or tweak hyperparameters. Anything but rewrite. Funny how fast blame shifts when frustration hits.
A couple years ago, you could hand-wave your way through vague questions and the model would spit out something surprisingly decent. It felt like a cheat code. Just type, cross your fingers, and wait for magic.
But at some point, the magic wore off—and the fix was learning LLM prompt engineering best practices. Prompts stayed fuzzy, but I started needing sharper, more targeted responses. It wasn’t the model. It was me.
Here’s the rub. We want outputs that actually move the needle: clear writing, analysis you can stand behind, calls you can defend. But models read plain text. We lean on nonverbal cues, context, and the stuff we never spell out—except the model only sees what’s written. If the prompt’s a blob, the answer’s a blob.
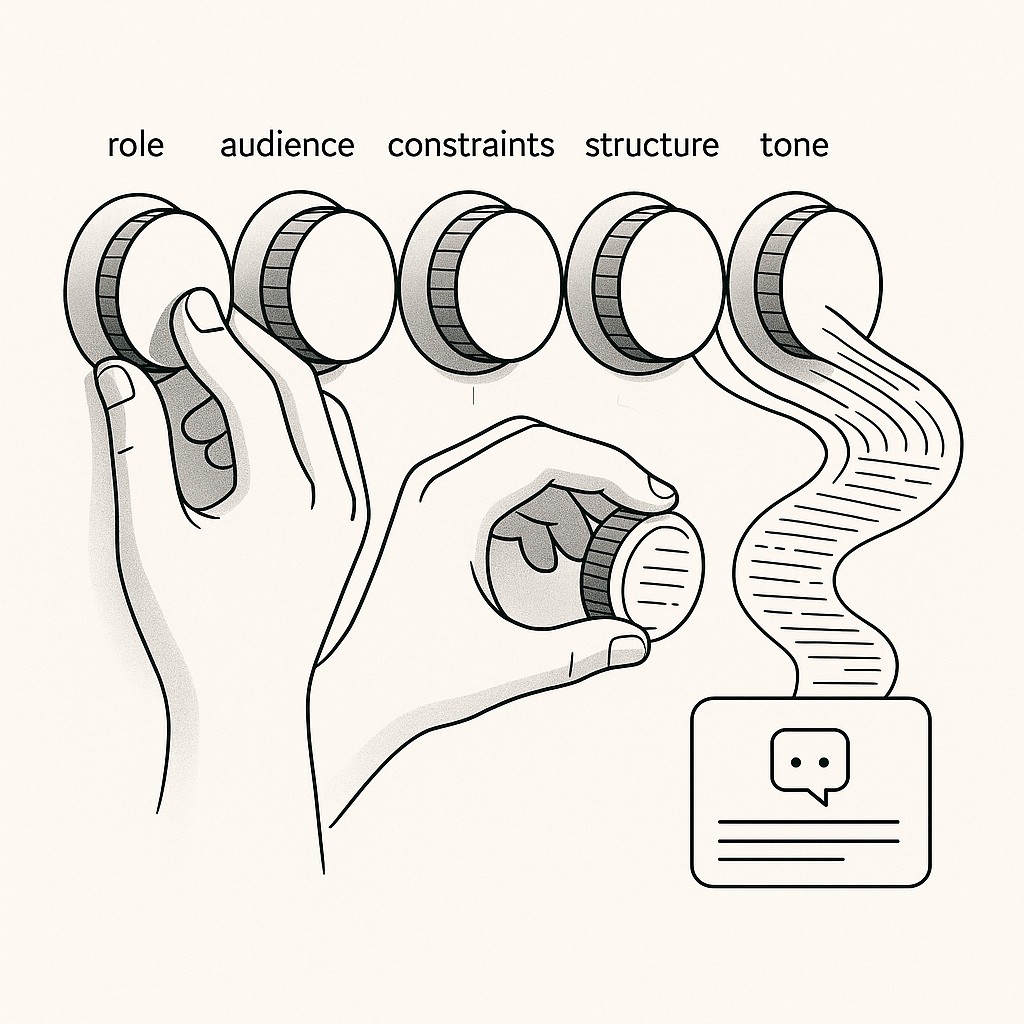
So here’s the thesis. If you encode role, audience, specific constraints, structure, and tone—all the context you’d give a sharp coworker—you’ll get reliable outputs. We’re moving from frustration to repeatable results, and it starts with how you write the prompt.
Why Explicit Inputs Matter
LLMs don’t read between the lines. They predict tokens based entirely on your prompt. Leave out context, it’s gone. No “common sense” unless you spell it out. This isn’t just a quirk; the right input sentence can flip a next-word predictor into a question-answering engine—context isn’t optional; it’s how the whole system tunes results. So, vague prompts get you vague results. There are no shortcuts.
Prompt design for LLMs isn’t about curiosity anymore. It’s about clarity under constraint. Treat your input like an interface—get specific, get repeatable.
Here’s where things get slippery. The phrases you choose tilt the whole interaction. If you call something “my great idea,” suddenly the model starts gunning for approval instead of critique. Even small tweaks in how you phrase a prompt swing the output, especially for tasks needing creativity or critique—let that sink in.
It’s easy to brush this off, but watch your words. They shape the answer. Neutral, tight wording invites honest reasoning. Loaded phrasing derails it.
Another lever: encoding the role and audience. You can hand the model a job description and a target reader. Use LLM prompts for engineers and tell it, “You are a staff-level engineer writing for a CEO,” and suddenly the tone, depth, and structure shift to match that scenario. The more you spell out, the less guesswork you get. And the closer the output lands to what actually works. Give the model something to aim for. Your technical context depends on it.
LLM Prompt Engineering Best Practices: How to Write Prompts That Actually Work
Every prompt I write now gets five inputs. No exceptions. Role, audience, constraints, structure, tone. Each one is a lever. Role says who’s speaking—a peer, a critic, a teacher—with implied expertise and perspective. Audience sets the target: engineers, managers, users? Constraints keep it tight: word count, evidence, steps. Structure asks for format: bullet list, argument, summary. Tone’s the mood: blunt, supportive, skeptical. Stack these, and ambiguity drops. Relevance jumps. Skip one, you open the door for noise.
I got in the habit of a pre-flight check before hitting send. Quick run-through: nailed the role, real audience, right limits, called for structure, picked a tone? Tick all five, and you move faster—not slower—because suddenly your pipeline gets stable.
This isn’t handcuffs or busywork. It’s more like tuning a guitar or picking which recipe to follow. Constraints box you in? Maybe. But they also make the thing playable, repeatable. Wide open space sounds good, until you try to play a gig with a guitar that won’t stay in tune.
Here’s my skeleton prompt—one of my structured prompt templates I use and adapt for almost anything technical.
“You are a principal engineer. Write for senior engineers making technical decisions. The goal: summarize tradeoffs between two database designs. Constraints: keep it under 200 words, cite at least two sources, outline concrete steps for migration. Output as a bullet list with a short intro and decision matrix. Tone: honest, assume skepticism.”
Every part is chosen: a clear role, target reader, what to do, hard limits, how to organize it, and the ‘personality’ to match. The model stops guessing and starts reasoning. I’ve seen framing cut down back-and-forth. Outputs snap into something you’d use without endless tweaking.
Give structure, not a straitjacket. Overscript it, you get rigid parroting or clunky repetition. Tell it what shape you want, not every single word. That’s how you get reasoning, not just regurgitation.
Small tangent—if you’ll indulge me. There was a stretch last fall where I kept fixing prompts for an internal tool; we’d get half-baked answers on infrastructure planning, then scramble to nudge the model with one-word tweaks. Someone cracked a joke about our prompts being like fragile APIs—change one parameter and the thing melted down or came back perfect, no easy in-between. Honestly, sometimes juggling those word choices felt less like engineering and more like guessing the secret handshake at a speakeasy. But I guess, like any input interface, there is a little dance to it.
How to Triage—and Fix—Prompt Failures
First step: pause and run the checklist. Was the role clear? Audience named? Objective spelled out? Constraints actually set? Structure defined? Nine times out of ten—it’s the prompt. No need to swap models or blame the system. Quick reality check: knowledge gaps tank output quality—44.6% of weak prompts missed key context, versus just 12.6% in strong ones. If your prompt feels underspecified, it probably is.
Let’s walk through an actual example. Last month I fired off, “Write a strategy memo about migrating our storage systems.” The model rambled for paragraphs without any real insight, just vague “pros and cons.”
So I rewrote: “You’re a CTO. Your audience is the CEO. The goal: clear, actionable migration recommendation. Constraints: keep it to three options, cite at least two industry benchmarks, and address risks explicitly. Use a numbered outline.” Nearly instant improvement—the answer hit the right tone, referenced real data, and laid out next steps I could use. Technically, what changed was the encoded inputs. The model linked structure and audience, cut the fluff, and gave focused analysis. Most prompt debugging is this: tighten your specs, watch the output quality jump.
Don’t get trapped scripting every line. You want to steer, not suffocate. Ask for steps, not sentences. Require evidence, not adjectives. Effective LLM prompts deliver the best outputs by providing a strong directional push, paired with loose wording.
When the output lands, make a note of what worked. If it’s still off, circle back to the checklist before reaching for a new model. Six months ago I kept making the same mistake—assuming a “better” model would fix underspecified prompts. Nope. It wasn’t the model. It was me.
Put role, audience, constraints, structure, and tone into practice—use our app to generate AI-powered content with clear prompts, get repeatable drafts fast, and iterate without wrestling the model.
Common Objections (and a Sustainable Practice)
I get the pushback. “This takes too long.” It feels like overkill to spend extra minutes building up constraints or spelling out who the prompt is for when deadlines are breathing down your neck. But let’s be real—I wish someone had sat me down and said: those minutes upfront save hours of rewriting, patching, clarifying. The cost is pennies compared to the headache of constantly tuning junk outputs. Makes you wonder how much engineering friction is just bad prompts. Still, I know I rush the checklist when things get hectic. Can’t say I’ve solved it.
Another one: “Aren’t constraints going to box me in? I want the model to surprise me.” In truth, constraints shape what’s possible. They narrow the search space, so the answers get sharper. If you’re exploring, loosen them. Wide constraints for discovery, tight ones for production. Think of it like testing code with different config flags: constraints help you steer, not stall.
And yes, the new models are “smarter.” It’s easy to expect too much. Better models lift the ceiling. Only good inputs lift the floor. Sharp prompts raise the baseline—no model will read your intentions off the keyboard.
Here’s what’s actually sustainable. Build a habit loop. Start with a skeleton template: role, audience, constraints, structure, tone. Run the prompt, review the results, tweak one lever. Save variations that work. Don’t start from scratch every time. In real-world workflows, prompt design is input engineering. And great inputs don’t happen by accident.
So next time you get vague or useless output, debug the prompt first. Clarity under constraint isn’t optional. It’s your ticket to repeatable, reliable outputs. If you revisit that “cheat code” mentality from earlier, you’ll see that good prompting isn’t about finessing magic. It’s building a baseline you can trust—and watching your technical writing and analysis finally click into place.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.