Outcome-Based Review Criteria: Clarity, Correctness, and User Impact
Outcome-Based Review Criteria: Clarity, Correctness, and User Impact


Why We’re So Obsessed With Spotting The “AI Tell”
I caught myself doing it again this morning. Mid-scroll on LinkedIn, staring at another post and thinking, did a human write this? The question sneaks up, like an itch you can’t quite locate. By the time I’m halfway through the feed, I realize I’m keeping score.
This habit has crept in everywhere. I’m always scanning for robotic phrasing, generic advice, just something that isn’t quite right. Here’s the thing. It’s rarely about grammar or punctuation. It’s more like spotlighting hidden shortcuts, sniffing out whether someone cheated on the test.
But as I sit with it, I notice a different pattern. What feels uneasy isn’t really the fact of AI writing. It’s our tangled relationship with effort, authorship, and how outcome-based review criteria should determine what makes content worthy of attention. Are we really mad about bland headlines and missed commas, or just that “earned insight” starts to feel fuzzy? A lot of times, I end up valuing what’s visible—the pain, the trial, the voice—more than the result itself, even if that’s not totally logical. I wish I could say it made perfect sense. This whole business about who deserves status, who gets to count as “real,” gets heated fast.
Most teams I work with get stuck here too. The business of catching fakes slowly morphs into a proxy war for fairness. We fixate on detection, and then actual useful work ends up sidelined because it doesn’t fit someone’s mold.
But what if we flipped it? The question isn’t “Was this made by AI?” It’s “Does this serve the reader?” If the value is there, does provenance matter as much? I’ll admit, sometimes I hesitate to trade one uncertainty for another, but it’s the only way forward that makes sense.
How AI Detection Turns Into Gatekeeping—And Why It Hurts Outcomes
That line between “guarding standards” and signaling status gets messy, fast. I see it almost every week. Someone pulls apart a phrase that’s too polished or vague, making a show of fairness. But these rituals rest on shaky ground. OpenAI’s own AI Classifier only correctly flagged 26 percent of AI-written text, and wrongly accused humans 9 percent of the time source. That means these fairness rituals land on unreliable ground. So what starts as a hunt for authenticity winds up feeling like theater—everyone reinforcing who belongs, without proof.
It’s easy for a team’s whole review cycle to get hijacked. Instead of digging into whether a post actually helps someone or solves a unique problem, people default to scanning for dead giveaways. Em dashes, buzzwords, robotic phrasing. Hours slip by debating, “Does ‘synergize’ mean this is AI?” or “Would a person say ‘unlock unprecedented growth’?” The talk shifts from outcomes to surface details. It starts to seem more important to guard against shortcuts than to deliver genuine improvement. Before long, stories that might have helped get tossed because they “feel synthetic.” All our energy goes toward policing vibes, not results. Clarity, usefulness, correctness—they get replaced by chasing patterns.
Here’s something that hit me sideways one afternoon. During a doc review, I found myself arguing with a teammate about whether “leveraging cloud-scale” was AI-generated jargon. Just over the shoulder, another engineer was quietly shipping a fix that cut build times in half. We were stuck on “synthetic feels” while the actual impact had already arrived. That was a wakeup call. The irony’s hard to miss.
There’s a quieter cost too. Whenever authenticity becomes a guessing game, people second-guess each other and themselves. That’s where Authenticity Anxiety kicks in. Instead of trusting the work, teams get suspicious, scanning for imposters and doubting anything that’s polished or new.
What if we drop the whole detective act? The real fix is to shift from policing process to a value-based content review—measuring actual value. Set clear outcomes—who it helps, what problem it solves, whether it actually works. The obsession with provenance fades. Reviews finally get back to moving things forward.
Serving the Reader Beats Spotting the Tell
I’ll be honest, I still get stuck. Sometimes a clearly AI-generated post stops me mid-scroll. Part of me rolls my eyes—part of me clicks “read more” just to see. Even with all my practice, sometimes a machine-made update has a nugget that sticks. I catch myself guessing the source, but increasingly, I’m not sure why I care as much.
Here’s the twist. The other week, I ran into a hashtag#AIContent post with fuzzy origins—could’ve been a template, could’ve been a real human riff. But the value landed. The insight was clear, the solution worked, and judging by the comments, it was helping folks. Does tracing lineage add anything? Sometimes, I’m not convinced.
Let me take a second for a tangent. When I was in college, I played pick-up chess in the park. There was this older guy—never said much—who’d show up with a battered clock and play anyone. When someone made a strong move, nobody cared whether it came from a computer, a book, or pure instinct. It was about the board, not the author. Sure, you’d have debate about style, but once the position settled, only the play mattered. The same thing happens in engineering. Nobody really pauses the sprint to argue about provenance if the problem is solved. The callback to those chess games sticks with me. It’s about impact, not so much the backstory.
So, let’s put it plainly. The question isn’t “Was this made by AI?” It’s “Does this serve the reader?” That’s the only test that holds.
Here’s where it gets practical. Make your standards explicit. Protect them by measuring what comes out—not how it’s made.
Outcome-Based Review Criteria: A Value-First Checklist to Replace Provenance Policing
Here’s the outcome-based review criteria checklist I lean on for reviews (and sanity). Start with the core: does this serve a real user? Does it solve a genuine problem? Then drill into the bones—correct, clear, maintainable, and does it pose risk for trust or compliance? Each part’s there for a reason. Keep your attention on outcomes, not guesswork about authorship.
For user value, I look for “who” and “why.” Last month I reviewed a pull request that cleaned up code style for three files. I almost approved it, but halfway through, I caught that nothing made sense until I framed who it helped. Only after I realized it was blocking daily workflow for Support did the review click.
Correctness means working tests, sample runs, or a minimal demo that actually proves the code does what it claims. Clarity’s simple—if I have to reparse a doc three times, it’s not clear. Maintainability means asking whether someone onboarded next quarter could pick this up. Trust and compliance risks: did someone import an unchecked package, ignore privacy, or flag an AI-generated legal section that could expose us? If not, stick to the outcomes. Don’t chase ghosts.
Before you even peek at code, anchor on user value criteria: who needs this, and what pain does it fix? I used to skip this step—reviewing flow and structure first. Mistake. The “who” and “why” is the frame. #Psychology
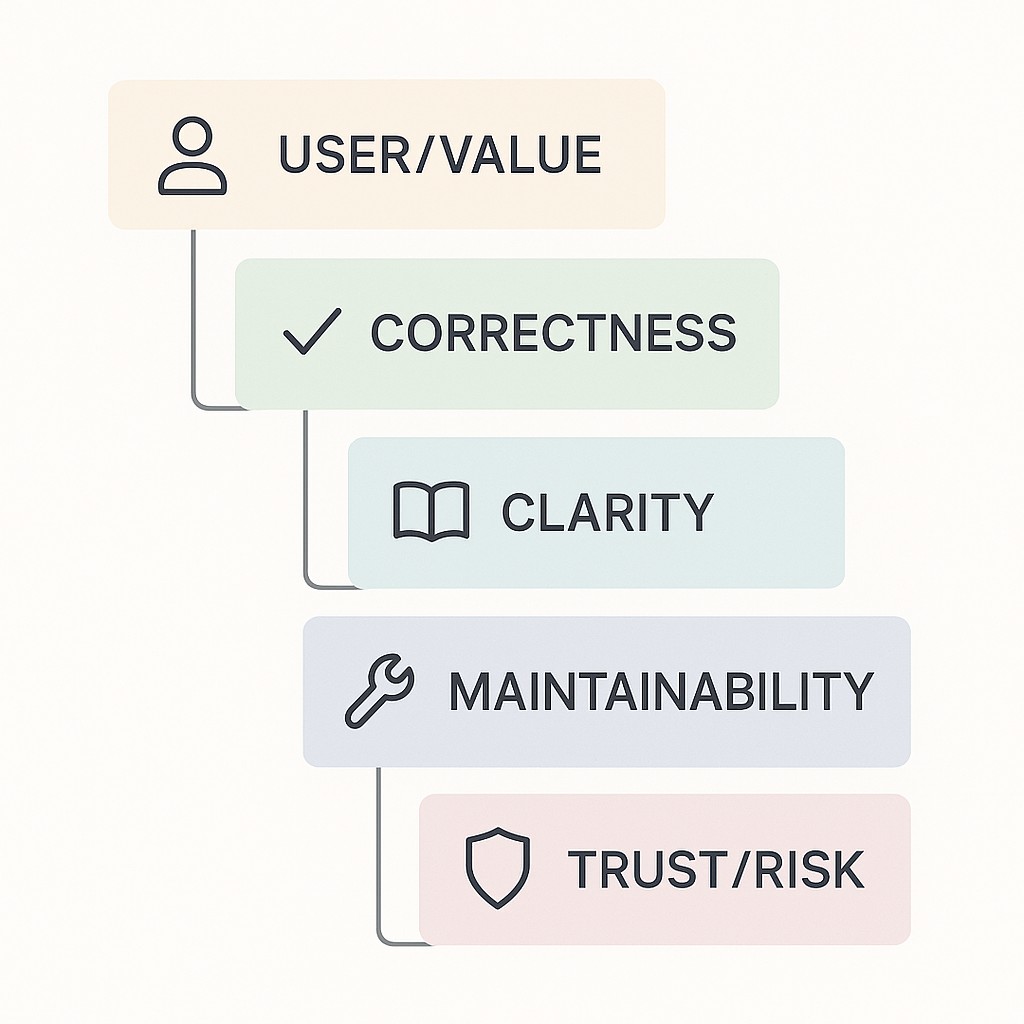
After you confirm user and value, move straight to evidence and clarity. Does the result prove itself, and can anyone follow? If trust or compliance risk shows up, then consider provenance. Otherwise, treat it as a provenance-agnostic review and skip detective work. Most drama dissolves once everything runs through this filter.
For example, when I review AI-assisted code to export customer data, my checklist is blunt. User/value: urgent fix for Accounts. Correctness: pulls fresh test data, works with dummy record. Clarity: top-down docstring, error messages that tell you what broke. Maintainability: not stuffed into a 200-line function. Trust: double-check on export permissions. What’s missing? I’m not squinting for “AI voice.” I watch for workflow, risk, and proof the right people are served.
That’s how reviews get faster, more focused, and actually human again. Value beats provenance—every time.
Answering the Doubts—Time, Fairness, and Compliance
I won’t pretend the shift is frictionless. Most people worry an outcome-focused evaluation adds more work, or worse, sidelines the effort real authors put in. That anxiety comes up in nearly every team I’ve coached—especially when a new checklist lands and everyone pictures longer meetings. Six months ago I was skeptical myself. But the honest reframe is simple. The discipline pays off fast. You spend less time chasing feels, more time confirming value. Once framing cuts down the back-and-forth, the work stabilizes and review fatigue trends down.
So how do you make it stick without turning it into another dreaded process? Start small. Pick one ritual, like the Friday code demo or a monthly doc review, and run the checklist there. You’ll see—the rhythm gets easier. User and value first, correctness and clarity next, then risk. Next week, swap in a different project or rotate who leads. When folks see outcome-first checks actually moving work instead of policing output, expectations reset. If you keep anchoring on criteria—who’s helped, what changed, is it safe—the less anyone hunts for the source or worries about status. Each cycle, ask: did this review surface a blind spot, or just confirm process?
What you’re committing to, really, is measuring work by what it delivers for users. Letting go of anxiety from playing judge over shortcuts and authorship. If you keep the criteria woven into reviews, outcome beats provenance. Trust finally starts to feel earned.
Focus on outcomes, not provenance, by using our app to generate AI-powered drafts tailored to your goals, then refine for clarity, correctness, and user impact so you can ship useful work faster.
To be blunt, I still can’t always shake Shortcut Suspicion when I see a too-slick headline or a recycled “growth hack” tip. Maybe that’s something we just have to live with. But I’d rather spend the time on value and impact than solve for authorship alone. The contradiction’s still somewhere in the mix. For now, I’ll take real change over perfect certainty.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.