Release Decision Risk Assessment: Ship or Refine with Confidence
Release Decision Risk Assessment: Ship or Refine with Confidence


The Technical Decision Playbook – Day 3: Robust vs. Ready to Ship
A few days back, our team ran a release decision risk assessment as we stared down whether to ship an 80%-ready feature, weighing speed against potential risk and rollback. It was the classic debate. We weighed a minor user-facing bug we could tolerate against the risk of breaking the core flow. We double-checked that rollback would be painless and, crucially, talked about how much future tech debt we might be inviting just to get things moving faster.
As an engineer (or an AI builder), you probably know this tension better than you wish you did. Move fast and break things, or take your time and get it right? Either path has its pitfalls. Fast usually means shipping issues. Perfect means never shipping.
Here’s how we handled it. We gave each risk a simple score. How bad would it be if something failed? Could we reverse it instantly if needed, or would cleanup be ugly? What was the long-term cost of cutting corners? Those scores made what felt like a “gut call” into something deliberate. The rollback plan made the risk so low we could move forward.
Funny thing is, a year ago I would have insisted we grind out every last polish before even thinking about deploying. That anxiety died off once I saw teams handle messy rollbacks without losing sleep. Scoring risk and reversibility turned an argument into a decision everyone could stand behind. Suddenly, the “ship or wait” frustration was out in the open and not lurking underneath.
So here’s the real work. Speed versus quality isn’t the choice we think it is. What we’re actually facing is risk versus reversibility. Decisions come down to whether they’re one-way or two-way doors. Most are reversible, which means the real focus is on making reversibility part of your process.
Let’s get practical. Here’s a scoring approach you and your team can apply today for instant clarity.
Release Decision Risk Assessment: Ship or Refine
I break it down into a when to ship framework with three scores, each on a 1–5 scale. First, what’s the impact if this fails? Next, how easy is rollback—could we flip a flag or hit a kill-switch, or is it tangled in data and user pain? Finally, what’s the long-term tech debt—will this shortcut cost us months of clean-up, or is it barely noticeable? Ship fast and get features out quickly, but risk bugs, tech debt, and messy fixes. A round of scoring turns hand-waving into a decision that feels grounded.
Stability-first is tempting. You hold the gate, raise standards, polish every detail. Prioritize stability and improve reliability, but risk slowing progress until nothing ships. Being too risk-averse can be just as dangerous as reckless pushing.
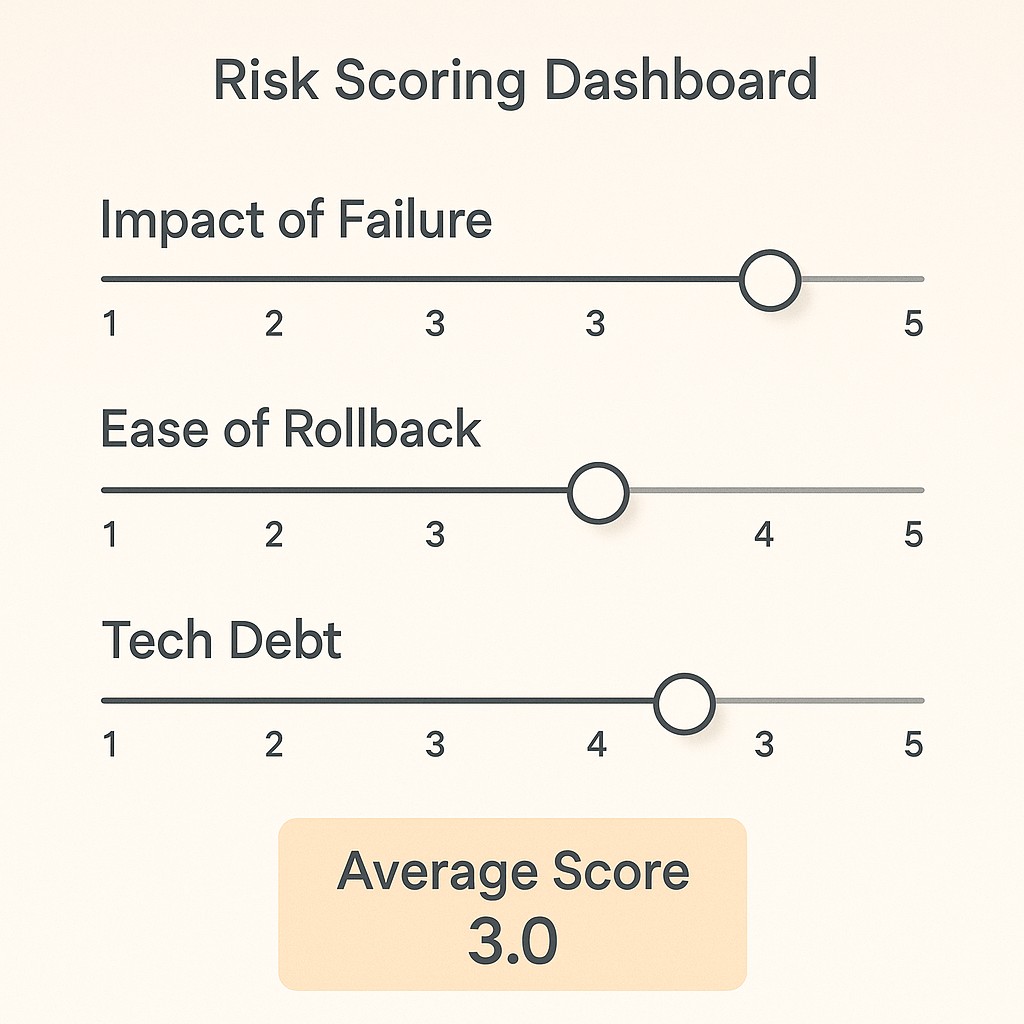
To make it concrete. For failure impact, look at which user flows or systems each change touches. Are core dashboards, login flows, or payments at risk, or just a harmless color tweak? Rollback should be measured by how quickly you can restore the old version. Clarify when to validate vs build before you flip the switch. If you have feature flags or a kill-switch, all good. If you need manual database patching, knock a few points. Tech debt acts like interest on a loan. Shortcut now means you pay it back later, probably when it hurts the most.
The difference between a strategic shipper and a reckless releaser? Reckless teams hope for the best, scramble in the aftermath. Strategic teams guess wrong sometimes, but make reversal simple and know what they’re trading on future effort.
Here’s the move. Average your three scores. If failure is minor and rollback is instant, ship now—the cost of being wrong is low and reversible. If impact is high and rollback is tricky, pause and refine. My bias usually leans toward shipping (because progress is addicting), but that rollback score is what keeps me honest and out of late-night firefights.
In your release decision risk assessment, think 80/20—if you’re about 80% ready, ship vs refine wisely. Lock in the last 20% only for high-scoring risks. Anything screaming “5” on failure or rollback pain gets another pass. Push now, harden where the cost gets sticky. You’ll find your own balance, but with clear scores, the tradeoff stops feeling like gambling and starts feeling like a controlled risk.
Translating Scores to Decisions: From Web Features to ML Deployments
Lay out the decision loop for risk-based shipping decisions. You score impact, rollback, and debt—right then, on the spot. You put numbers on it, talk it out, build stakeholder buy‑in for bets. Decide if you ship or hold. If it’s a ship, set guardrails before code goes live. Most days, this process takes so little time you wonder if it’s enough. Ten minutes to sidestep days of regret.
Say you’ve got a small UI tweak—maybe an icon or a tooltip. Bug impact is trivial, and you can flip a flag to undo it if users see anything odd. Ship. Contrast that with a payment system update. Impact jumps way up: double-charged users, refunds glitching, rollback isn’t simple. You pause, tighten, maybe pull in another pair of eyes. If you’ve actually been in these shoes, take a minute. Think about a past project—did you get the balance right? Would you make the same choice today? I’ve rushed out “small” changes and spent triple the time untangling the fallout. It’s not just about code—it’s about how much failure you can stomach.
ML is its own beast, but the same logic holds. If you’re shipping a model and can monitor errors live with a simple toggle to revert, you ship. Metrics show when things tank. But if it’s a schema change buried deep in your data pipeline, or logic inside training code, rollback can threaten actual user data. That’s the point where I always want a long pause, maybe ask for a dry-run, before touching production.
There’s a recurring worry that this scoring eats valuable time, that it’s too fuzzy, or that rollback feels safer than it really is. The honest truth is, the scoring step itself takes minutes. The squishiness fades once you broadcast clear heuristics—impact, reversibility, debt. And rollback safety isn’t a checklist—run a drill and you spot the gaps everyone missed. I’ve called features “rollback ready” only to stage a simulated revert and realize the database patch was going to take all night. I know the value of the dry-run, yet sometimes I still cut corners and regret it. Not proud of that.
Next up, let’s get into the actual guardrails and sneaky traps. Those matter more than fancy tools.
Making Reversibility Real: Guardrails and Gotchas
There isn’t a secret catalogue of perfect tools. What you want are guardrails that keep shipping safe without turning everything into a month-long slog. Most teams start with feature flags. Flags mean you can roll out just a slice to users—flip them off instantly if pain hits. Then staged rollouts and canary deployments—ways to embrace risk safely with guardrails. Ship to 1%, watch like a hawk, expand if it’s clean. Automated rollback is my stress reliever because it’s grounded in rigorous rollback strategy evaluation. Set conditions, let errors trigger a revert, and avoid frantic midnight debugging. Good telemetry on top shows you instantly when stuff goes sideways. Simple matters. You don’t need endless lists of risks—tracking seven to 12 key risks per SLI keeps guardrails real.
Here’s a messy moment—I spent half a Saturday at the crag, resetting my anchors on a bouldering route in some borrowed shoes. Felt wrong every time, like my foot would slip. I realized afterward that I’d been so obsessed with the gear itself, I forgot to check the rock was stable. Same pattern shows up in software. Fancy guardrails don’t save you if the actual foundations aren’t solid. Build trust on simple anchors and check them from scratch each time.
The traps. Irreversible database migrations, hidden service coupling, logic that spreads state in weird directions. These are changes that demand a flag and a triple-check before you press ship. If rollback means fixing live data or wrangling dependencies all night, better to stop and do the hardening first.
Not every feature hangs on reversibility alone. Compliance-heavy code, security refactors, infrastructure shifts that ripple through multiple platforms—sometimes “just roll back” doesn’t cut it. Harden everything up front, validate beyond sense, and treat reversibility as a bonus, not a project plan.
The main thing: guardrails let you go faster, but only if you actually use them. Check anchors, skip the known traps, and keep moving, but don’t assume safety is automatic. Sometimes I still treat reversibility as a comfort blanket, even when I know deep down it’s only half the solution. There’s a tension there I haven’t resolved.
Ship with Confidence: The Checklist
Great engineers don’t aim for perfection. They balance speed and risk. That’s all this is: score how bad failure could be, check how rollback works, don’t ignore debt. Use the 80/20 rule—the last stretch of polish only matters when risk spikes. Set up guardrails, make your decision, and review later, especially after the stakes were high. The best performers don’t move slow—they ship almost a thousand times more often, recover six thousand times faster, and keep outages lower. Velocity and safety are partners, not rivals.
What I want you to do? Next release. Pick the feature, run the scores, decide—ship (with safeguards) or pause and harden the risky bits. Don’t wait for “perfect” heuristics. You’ll get sharper every time.
If you’re a busy engineer or AI builder, use our tool to turn rough notes into clear, AI‑powered posts, so release updates, docs, and write-ups ship as fast as your code.
Bottom line. Ship when being wrong is cheap and reversible. Refine when you know being wrong is expensive and sticky—that’s how you keep moving and keep disaster off the roadmap.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.
You can also view and comment on the original post here .