The Software Engineering Hierarchy of Needs: Build Strong Foundations Before You Scale
The Software Engineering Hierarchy of Needs: Build Strong Foundations Before You Scale


Why Chasing Features Alone Isn’t Enough
A few months back, I watched a talented team celebrate the launch of a shiny new set of growth features—personalized dashboards, instant recommendations, a social-sharing widget. All the buzzwords. The energy was contagious at first. Big push, tight deadline, lots of excitement.
But underneath, something just nagged at me. Bug reports kept landing in Slack, almost one after another, and every single one traced back to error handling that hadn’t kept up with the glossy front end. Then came the critical issues. APIs started timing out for reasons nobody could immediately explain, logs went missing just when we needed them most, and some user data slipped through holes that we should’ve sealed months before. The release made headlines for a weekend, but by Monday, users were already frustrated and the on-call rotation was a misery.
I won’t pretend I haven’t been part of teams who charged ahead like this, ignoring the software engineering hierarchy of needs and chasing shiny features instead of shoring up the basics. It’s easy to get swept up in growth until the foundation starts cracking and every new feature actually slows you down. Maybe you’ve felt this too—the chaos after the confetti settles.
Somewhere around two years ago, after a particularly rough launch, I caught myself just staring at an error log in the middle of the night, wondering why the same kinds of issues kept sneaking back into production. It was the fourth time that month I found myself trying, and mostly failing, to make sense of incomplete logs and half-baked fallbacks.
For whatever reason, I thought about the mess my garage gets in every spring—boxes stacked half-open, cables snaking everywhere. I spend a day cleaning, make things look visible and tidy, and still: the next week, something new falls behind the shelf. Software feels like that sometimes, too. You can organize and polish all you want, but if the shelves aren’t sturdy, the boxes just tip over again.
That got me thinking. What if we defined a software hierarchy of needs? Features are important, sure, but systems need care and the right sequence to really thrive. What if we thought of software as something dynamic—like a living system that grows, evolves, and needs attention to stay healthy?
Is your software just surviving—or thriving? If you map out your recent releases, are you investing where it matters most? Might be time to look closer.
What I’ve found helpful is walking through a practical software maturity model. Figuring out the lowest weak layer in your system, focusing backlog work there—and making sure the next time you grow, you do it on actual solid ground.
The Software Engineering Hierarchy of Needs: The Five Layers That Build Lasting Software
Let’s keep it simple. Every system needs a strong foundation, and that foundation grows up through a clear hierarchy. You just can’t stack features on shaky ground and expect stability. Each layer of technical maturity builds on the one below. This isn’t just theory—the hierarchy echoes intentionally layered approaches like AWS Well-Architected, which builds maturity across operational, reliability, and security dimensions to support scale and resilience. Shortcuts feel tempting, but treating these layers as optional just piles up future work and headaches. Honest reflection about where your system stands is essential. I’ve seen teams skip steps and, well, it usually turns chaotic.
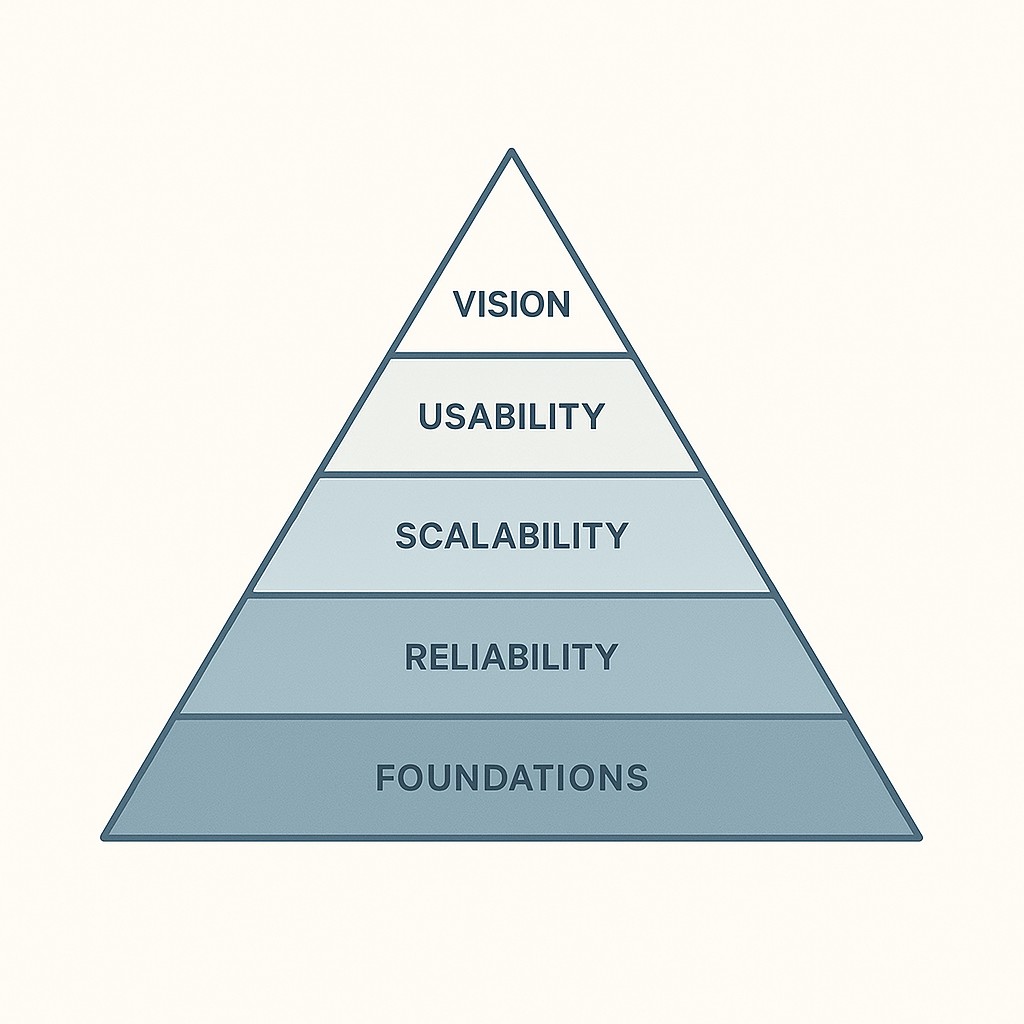
At the bottom is the Existence Layer. Day-one basics: your app runs, returns the right results, and stays up under normal load. It handles obvious errors. It doesn’t crash when ten people sign in at once. If your system struggles at this level, nothing above it really matters. Small cracks become outages, fast.
Next is Security & Shelter—protecting what you’ve built. Security by default, locked-down surfaces, backups that actually get tested, redundancy ready for the unexpected. It’s the difference between sleeping well at night and waking up to a panic message about leaked data. You can recover if something goes wrong.
Once you’ve got Shelter, focus on Interaction. Users (or systems) need to talk to your software easily and reliably. Clean APIs. User flows that don’t break. Observability that actually shows what’s happening, with fast feedback when things go wrong. This layer isn’t just about visibility. It’s about making problems fixable so your team isn’t flying blind.
With interaction dialed in, now you can layer on Growth. Performance tuning, scaling, safe experimentation. Automation where it matters—traffic splitting, spinning up servers, rolling out new features with guardrails. If you’re pushing for growth without solid interaction or shelter, you’ll just make problems louder.
At the top sits Vision. This is where you make product purpose real with technical capability, seeing the system evolve toward true goals. Product vision defines the “why” of your software, but technical growth ensures the “how.” If you want your product to last, let the vision stay in conversation with every layer below. Otherwise, strategy floats away from reality.
The real trick is this. In layered software maturity, each layer depends on the strength of the ones beneath it. If you spot churn or instability, map your system—find the lowest weak spot. Capability sequencing often comes down to deciding to build or buy at the right time. Prioritize reinforcement there before chasing the next flashy idea. When the foundation holds, innovation isn’t just possible. It’s sustainable.
Mapping Your System’s Weakest Link (And Why It Matters)
Start with a clear-eyed inventory. No fancy docs or templates needed. Gather real examples of what your system does—not what’s promised. Map each capability to one of those five layers. Does your app stay online no matter what (Existence)? Is sensitive data locked down (Security & Shelter)? Can you spot and respond to errors fast (Interaction)? Have you automated scaling bottlenecks (Growth)? Does your product vision guide technical decisions (Vision)?
The critical move is to hunt for the lowest weak layer—the spot that feels brittle or always needs patching. Skip a layer, and you risk chaos. Bugs, poor performance, frustrated users. Bottlenecks often come from planning gaps, too, which contribute to about 34% of technical debt events in teams. See your weakest layer and you’ll usually find the source of most trouble above it.
Before this starts sounding like a grueling backlog audit, keep it practical. Take ten minutes today to reflect. Which layer of your system needs attention? If you’re not sure, ask your on-call engineer what’s been waking them up lately.
Typical scenario: a team with beautiful UI experiments and creative growth hacks, but brittle error handling and zero real-time alerts. Interaction is weak, so outages keep happening—even as the “top” features look shiny. Trouble stays invisible and users get frustrated. Honestly, you can spot this pattern just glancing at your last three incidents.
If you’re still not certain, picture tending a houseplant. You start with water and decent light, then notice rootbound tangles that need space. Skip the basics and you get droopy leaves—no matter how good your fertilizer is. Software’s no different. Lush growth, healthy roots first.
I’ll admit—once I pushed for a flashy launch, convinced that buzz would outweigh missing operational polish. It didn’t. We spent weeks untangling small outages and frantic escalations that would’ve been trivial with better groundwork. That experience made it clear: mapping layers and focusing on the lowest weak point isn’t about slowing down. It’s about dodging messes that steal your time for months. The hierarchy itself would have made everything less painful and way faster to fix. I know we’re all tempted to skip steps, but it never pays off in the end. And honestly, even now, I sometimes realize I’m halfway through a new project before I’ve taken stock of which layer actually needs work. Still working on that.
Sequencing Backlog Work for Durable Growth
Once you’ve mapped your weakest layer, the real work is quietly straightforward. Adjust your backlog to build technical foundations first, shoring up that fragile spot before anything else. Don’t overthink it. If error handling is shaky, start with small fixes—circuit breakers, better validation, more graceful fallbacks. If observability is patchy, prioritize coverage. More logs, alerts that catch real problems, dashboards someone might actually check. For security gaps, lock down surfaces and roll out baseline protections, even if it’s just two-factor for admin panels and scheduled backup jobs. Fill redundancy holes with quick-win failovers or test restores. You want the ground getting firmer, not perfection overnight. Once stability improves, swing back to growth work with more confidence.
It’s normal to worry this will slow feature velocity. I get DMs every single time a team leans into hardening layers first. But here’s the reframe: prioritizing resilience over speed is the best way to cut rework, dodge firefights, and accelerate real innovation.
This isn’t just theory. High-performing teams that reach true Flow focus first on solid engineering practices like loosely-coupled architectures, CI/CD, and workplace flexibility (DORA 2022). You can jump ahead to innovation or flashy features, but skipping foundational layers will slow you down—or knock things over entirely. Brittle foundation means every new feature risks breaking something below, forcing you into endless round-trips chasing bugs. Harden the foundation and teams move with more ease. Deploys actually stand on solid ground and sleep gets easier. What seems like a detour up front becomes a shortcut to sustainable speed.
There are always real trade-offs, so prioritize reliability over features when weighing security vs scale and features vs redundancy. You have to choose what’s “enough” at each step. Just be intentional. Set acceptance criteria, revisit guardrails, and timebox deeper work so you don’t drift forever. Long-term, layers shift as your app evolves, so recalibrating backlog priorities is healthy.
This approach does three things. Protects your users. Increases delivery speed. Makes growth stick for the long run. You don’t just get stability—you get a system that’s actually ready to thrive, not just survive.
Putting the Layers to Work: A Real Example and Next Steps
Let’s talk through a real scenario I keep seeing. A team launches an AI system that nails model performance. Predictions are sharp, demos impress, stakeholders cheer for growth metrics. But then, silent failures creep in. Users report weird behavior—a few inputs vanish, whole data batches disappear. Turns out, basic logging wasn’t built for edge cases, and retry logic for flaky endpoints… just not there. The system rocks at Vision—everyone tracks the “why,” the model is dialed in. But Existence and Interaction are weak. Logs go flat when things break, data meant to auto-retry just goes missing. So new features? They only magnify cracks instead of fixing them.
What changed? The team slowed down. They reinforced bottom layers—added resilient logging, not just for the happy path, smart retries for network blips, real-time alerting. Outages dropped, users got answers instead of blank screens, rolling out new features became less scary. They stopped firefighting symptoms and fixed what was invisible. This lesson pops up again and again. Skipping groundwork piles up trouble for tomorrow.
Now, those engineers keep a standing checklist. Before every growth push, shore up the least mature layer first. It isn’t glamorous. The urge to “just ship” is real, and sometimes I even catch myself half-drafting a cool new idea before double-checking observability basics. But weighing those tradeoffs of POC versus production helps you know when to harden before scaling. Most easy wins—robust error handling, retriable operations—pay back instantly when incidents shrink and new features roll forward without drama.
I’m genuinely curious. What layer do you see most often overlooked in software development? Let me know in the comments—I’d love to hear. Different teams stumble in different places.
If you’re looking for a next step, here’s what I tell my teams. Establish error budgets today even if it’s just a sticky-note threshold. Expand observability beyond production. Review access controls with the whole team. Set a date for scale tests in the next quarter. Don’t wait for a hotfix to force it—just start at the biggest gap.
If you share your engineering lessons regularly, use our AI content tool to draft clear posts, repurpose notes into LinkedIn or blog-ready pieces, and keep your voice consistent without spending hours editing.
Stepping back, that painful release at the start wasn’t just bad luck. It was a signal that real innovation starts by shoring up the lowest weak layer. Let’s build systems that thrive. Top to bottom.
Enjoyed this post? For more insights on engineering leadership, mindful productivity, and navigating the modern workday, follow me on LinkedIn to stay inspired and join the conversation.
You can also view and comment on the original post here .